wikiclip
a tool to find wikipedia articles inspired by an image
background
give wikiclip a try before reading
I still remember my first Wikipedia search. After spending years reading physical encyclopedias and hours in Encarta, I stumbled upon Wikipedia. I was mesmerized, but didn't tell my parents out of the fear that this "wiki" was somehow derived from Wicca (the religion).
I love the process of stumbling upon new articles. A few years ago, I made a site called Wikitrip where you can find articles that are nearby. I love using it on a road trip or in a new city to find interesting places around me.
But there are only so many articles with a location. Often, you want to know more about what you see around you. What if you had a tool that could look at an image and return similar articles on Wikipedia.
method
The basic premise is to use CLIP to create an embedding database Wikipedia articles. We'd then query this database using a CLIP embedding from an image. Because CLIP embeds images and text into a shared space, the closest embeddings to the image will be the most relevant articles.
data
The first challenge is scale. English Wikipedia has nearly seven billion articles. Pulling each of these articles would be infeasible. So I first tried pulling articles alphabetically, and came back with numerically-listed articles that were odd and uninteresting.
Instead, I took a few different approaches to pull a better sample. Wikipedia editors are meticulous. They maintain a list of "Vital Articles" at five different levels of importance ranging from the 10 most important topics in level 1 down to 50,000 articles in level 5. This is a great starting point to index releavant content.
Wikipedians also classify articles into quality categories. I pulled all articles listed as Good Articles, and A-Class Articles. There are about 160,000 articles in these categories, though they are not all unique as they overlap with the vital articles.
To extend coverage further, I retrieved the 1,000 most popular articles from each month from 2016 through the present. This didn't add a great volume of data, but it did provide a few more interesting articles that wouldn't have been picked up otherwise.
embeddings and database
CLIP can only process 77 tokens of text (55-60 words) at a time, so I pulled either the page "extract" (roughly the first paragraph of the article) or the article title if an extract wasn't available. I then used CLIP to embed the text and stored the embedding, article id, and an article hash to check for duplicates.
In total, I added 104,686 articles to the database. People talk a lot about the size of machine learning models and GPU acceleration, but they can often forget that running them locally on the CPU is quite reasonable. Pulling the articles took much longer than computing the embeddings. In the end, the the db file comes to ~500 mb in size. The full process took 30-45 minutes.
querying the database
Finding articles most similar to an image in the database is pretty simple. I use the the same CLIP model to embed an image, and then compute a dot product on the normalized vectors (equivalent to cosine similarity) to score and find the most similar articles. Depending on the processor, this takes less than a second per query.
hosting stack
I ran everything locally to start, but enjoyed using it enough that I wanted to host it. This website is all static, hosted for free on GitHub Pages. This project required a database, a backend function to compute the embeddings, and a frontend interface.
I used Supabase to host a postgres database. I used pgvector to query the embeddings, and created an HNSW index on the embeddings to make queries fast.
To compute CLIP embeddings for the input images, I created an AWS lambda function with a custom docker image. This made it possible to pre-load the CLIP model and make processing as fast as possible for little cost. The lambda instance is a simple ARM processor, again showing that a rack of GPUs is not always necessary to do cool things with neural networks.
The frontend is a simple static page hosted on GitHub Pages that queries the lambda function. It's fairly straightforward with vanilla javascript, html, and css.
results
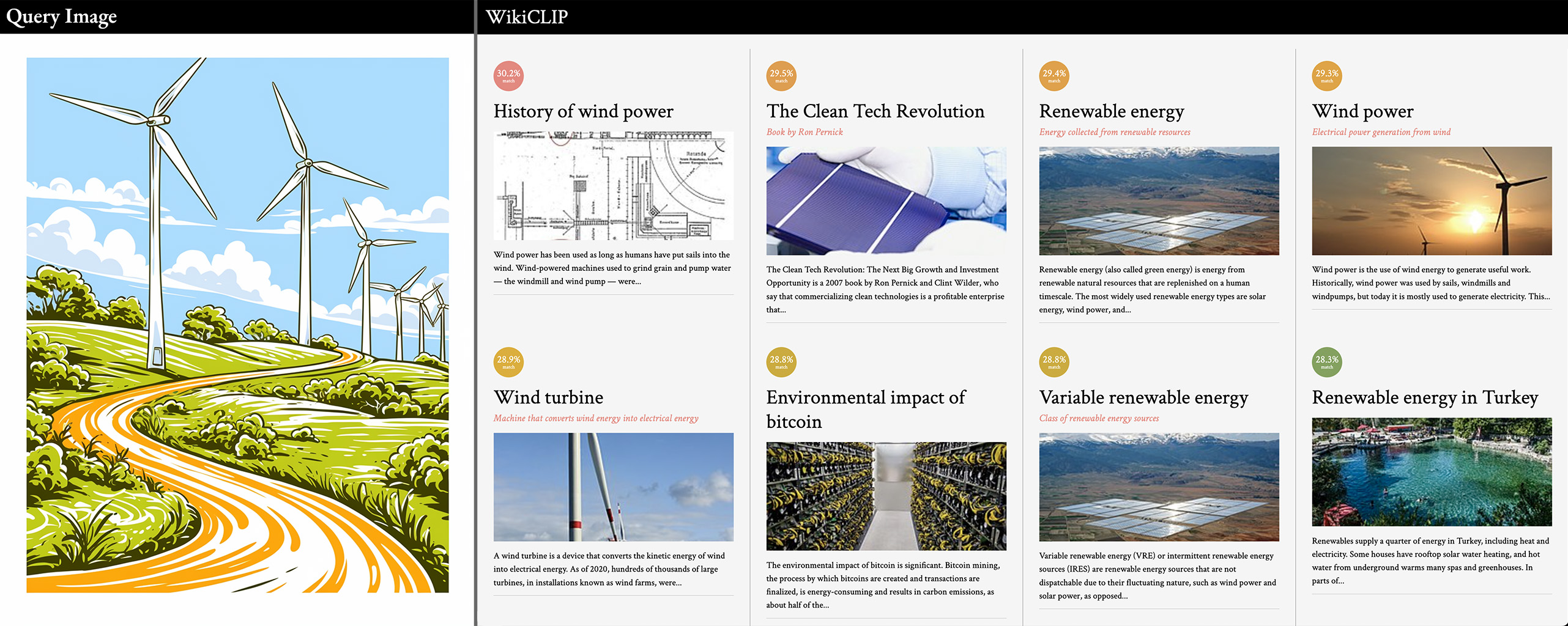
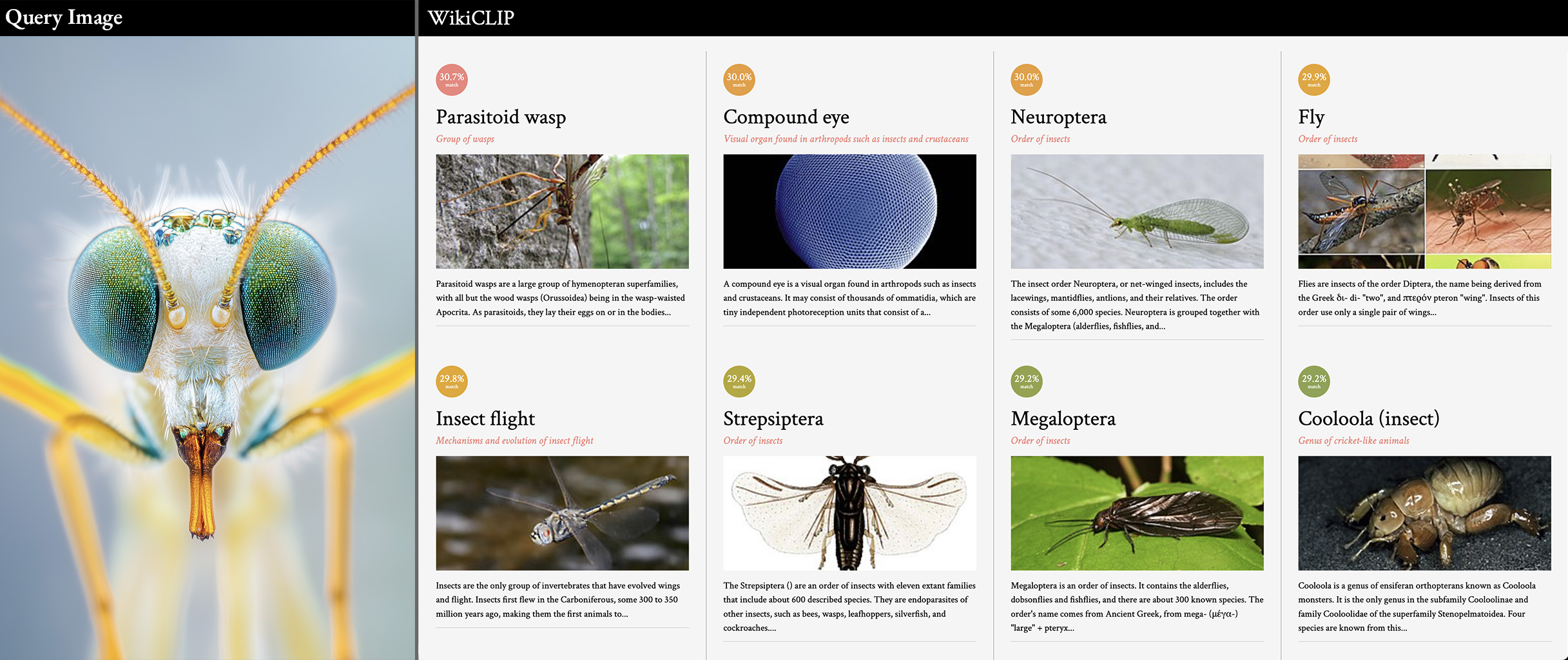
I'm quite happy with how it all works! Given the limitations of CLIP and the limited number of articles, I find it to be quite delightful at surfacing articles that are similar, but not an exact match. Here are a few examples:
looking at objects in the real world
querying with an illustration
querying with a photo
code
The code isn't in a polished state, but can be found at https://github.com/clkruse/WikiCLIP.
conclusion
Overall, I'm pretty happy with the results and being able to put it together quite quickly. Interestingly enough, creating the local demo was done within a weekend. The real challenge was figuring out how to host it. I don't think this is necessarily a challenge for everyone, but it's an area where I have the least experience.
I love seeing the results. My favorite part is that this is not intended to be a Google Lens clone that returns exact matches. Instead, it surfaces articles that are similar, but at times totally unexpected. It also reveals the unexpectedly literal nature of CLIP. As I play with WikiCLIP, I realize it has a personality closer to Amelia Bedelia than Sherlock Holmes.
what would i do next
- I used the smallest CLIP model. I'm curious if the results would get better with a larger model.
- I became a bit of a data hoarder with the Wikipedia scraping. Maybe I'd scrape all of the "B-Class" articles to get a lot more data.
- It's funny to take a picture of a person and see what results are similar. I think this could be a first-class feature if I pulled articles from a list of notable people.
- Clean up the code to make it more clear about what I did and let other build on top of it.